I was presenting a session on how to read execution plans when I received a question: Do you have a specific example of how you can use the query hash to identify similar query plans. I do, but I couldn’t show it right then, so the person asking requested this blog post.
If you’re dealing with lots of application generated, dynamic or ad hoc T-SQL queries, then attempting to determine tuning opportunities, missing indexes, incorrect structures, etc., becomes much more difficult because you don’t have a single place to go to see what’s happening. Each ad hoc query looks different… or do they. Introduced in SQL Server 2008 and available in the standard Dynamic Management Objects (DMO), we have a mechanism to identify ad hoc queries that are similar in structure through the query hash.
Query hash values are available in the following DMOs: sys.dm_exec_requests and sys.dm_exec_query_stats. Those two cover pretty much everything you need, what’s executing right now, what has recently executed (well, what is still in cache that was recently executed, if a query isn’t in cache, you won’t see it). The query hash value itself is nothing other than the output from a hash mechanism. A hash is a formula that outputs a value based on input. For the same, or similar, input, you get the same value. There’s also a query_plan_hash value that’s a hash of the execution plan.
Let’s see this in action. Here is a query:
SELECT soh.AccountNumber ,
soh.DueDate ,
sod.OrderQty ,
p.Name
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod ON sod.SalesOrderID = soh.SalesOrderID
JOIN Production.Product AS p ON p.ProductID = sod.ProductID
WHERE p.Name LIKE 'Flat%';
And if I modify it just a little, like you might with dynamically generated code:
SELECT soh.AccountNumber ,
soh.DueDate ,
sod.OrderQty ,
p.Name
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod ON sod.SalesOrderID = soh.SalesOrderID
JOIN Production.Product AS p ON p.ProductID = sod.ProductID
WHERE p.Name LIKE 'HL%';
What I’ve got is essentially the same query. Yes, if I were to parameterize that WHERE clause by creating a stored procedure or a parameterized query it would be identical, but in this case it is not. In the strictest terms, those are two different strings. But, they both hash to the same value:Â 0x5A5A6D8B2DA72E25. But, here’s where it gets fun. The first query returns no rows at all, but the second returns 8,534. They have identical query hash values, but utterly different execution plans:
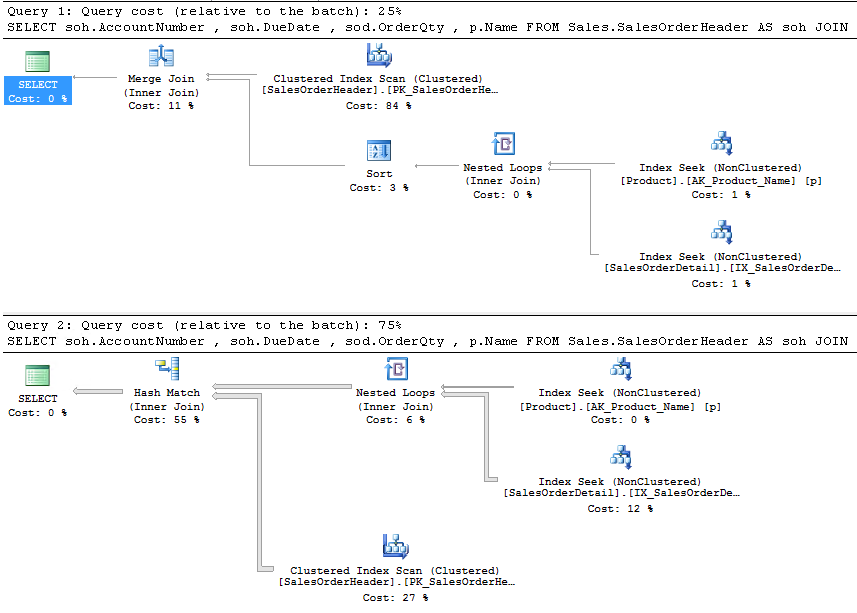
Now, how to use this? First, let’s say you’re looking at the second execution plan. You note the scan of the SalesOrderHeader clustered index and decide you might want to add an index here, but you’re unsure of how many other queries behave like this one. You first look at the properties of the SELECT operator. That actually contains the query hash value. You get that value and plug it into a query something like this:
SELECT deqs.query_hash ,
deqs.query_plan_hash ,
deqp.query_plan ,
dest.text
FROM sys.dm_exec_query_stats AS deqs
CROSS APPLY sys.dm_exec_query_plan(deqs.plan_handle) AS deqp
CROSS APPLY sys.dm_exec_sql_text(deqs.sql_handle) AS dest
WHERE deqs.query_hash = 0x5A5A6D8B2DA72E25;
This resulted in eight rows. Yeah, eight. Because I had run this same query different times in different ways, in combinations, so that the query hash, which is generated on each statement, is common, but there were all different sorts of plans and issues. But, a common thread running through them all, a scan on the clustered index as the most expensive operator. So, now that I can identify lots of different common access paths, all of which have a common problem, I can propose a solution that will help out in multiple locations.
The problem with this is, what if I modify the query like this:
SELECT soh.AccountNumber ,
soh.DueDate ,
sod.OrderQty ,
p.Name,
p.Color
FROM Sales.SalesOrderHeader AS soh
JOIN Sales.SalesOrderDetail AS sod ON sod.SalesOrderID = soh.SalesOrderID
JOIN Production.Product AS p ON p.ProductID = sod.ProductID
WHERE p.Name LIKE 'HL%';
Despite the fact that this query has an identical query plan to the one above, the hash value, because of the added p.Color column, is now 0xABB5AFDC5A4A6988. But, worth noting, the query_plan_hash values for both these queries are the same, so you can do the same search for common plans with different queries to identify potential tuning opportunities.
So, the ability to pull this information is not a magic bullet that will help you solve all your ad hoc and dynamic T-SQL issues. It’s just another tool in the tool box.
For things like this and a whole lot more, let’s get together in November, 2013 at the all day pre-conference seminar at SQL Saturday Dallas.
UPDATE: In the text I had incorrectly said this was introduced in 2005. It was 2008. I’ve updated it and added this little footnote. Sorry for any confusion.
Grant,
I think I missed something. How did you retrieve the original hash?
In this example I got it from the execution plan. It’s in the SELECT operator (or, for other queries, the INSERT/UPDATE/DELETE operator). I mention it right after the first execution plan. You can also get it by querying the DMOs directly, but you’ll have to filter for the right query, probably using the SQL text.
Great article ! You mention these features were added in SQL 2005. Really wish they were in that version as they would have made my job so much more easy. Unfortunately for me query_hash and query_plan_hash were introduced in SQL 2008.
Oops. Sorry. My mistake. I’ll fix that in the text.
Great article, Grant! Question:
Using the AdventureWorks2012 database on SQL 2012: I ran DBCC DROPCLEANBUFFERS and DBCC FREEPROCCACHE to start then I ran the provided queries.
The first and second query returned the same query_hash values and the third query returned a different query_hash as expected. However, NONE of the queries return the same query_plan_hash value.
query_hash query_plan_hash
0x5A5A6D8B2DA72E25 0x2ACC3883040EEF73
0xABB5AFDC5A4A6988 0x4931966B76DA9FC3
0x5A5A6D8B2DA72E25 0xD936E5DA6A677627
This is to be expected between the first and second queries, but I expected the second and third plans to be identical. At first glance they visually are, but upon closer inspection they are very slightly different.
The second query calculates the following costs:
-0% on the AK_Product_Name Index Seek
-42% on the PK_SalesOrderDetail Index Scan
The third query calculates the following costs:
-1% on the AK_Product_Name Index Seek
-41% on the PK_SalesOrderDetail Index Scan
What explains this? SQL Server 2012? AdventureWorks2012? Something else I am over-looking?
usually, but not always, I attribute that stuff to differences in the statistics in Adventureworks. It could be that you and I have a different version. It could be we have the same version but you, or I, have updated the statistics. That’s likely to lead to differences. In my tests, they did return the same hash value. You can try it with different queries. You should be able to replicate it.
Thanks Grant! I suspected as much!
Great article!! Very practical! Will apply this approach to my daily routine of performance tuning. Thank you!
Great article! Trying to use use the query_hash to create EVENT SESSION with a filter like this:
WHERE ([sqlserver].[query_hash]=(15169206896904297700.))
I’m using Query Store where I found a query_hash inside the sys.query_store_query SystemView.
The value in sys.query_store_query is 0xD283D94D8662DCE4
If I cast this to BigInt I get -3277537176805253916, which is not correct.
SELECT CAST(0xD283D94D8662DCE4 AS bigint)
I’m trying to make a script which automatically makes a script to create the event session Extended Event like this:
CREATE EVENT SESSION [Query Hash] ON SERVER
ADD EVENT sqlserver.sp_statement_completed(
ACTION(sqlos.task_time,sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.database_name,sqlserver.sql_text,sqlserver.username)
WHERE ([sqlserver].[query_hash]=(15169206896904297700)))
ADD TARGET package0.ring_buffer(SET max_memory=(10240))
WITH (STARTUP_STATE=OFF)
GO
Hmmm… Let me experiment with this and I’ll get back to you.
A little research, a couple of experiments, and this should do it:
DECLARE @decimal AS DECIMAL(20,0)
DECLARE @a BIGINT
SET @a = 0x7fffffffffffffff
SET @decimal = CAST((0xC07B3A34A41CC264 & @a) AS DECIMAL(20,0))
SELECT @decimal
Got that from here: https://blogs.msdn.microsoft.com/sql_pfe_blog/2013/08/19/correlating-xe-query_hash-and-query_plan_hash-to-sys-dm_exec_query_stats-in-order-to-retrieve-execution-plans-for-high-resource-statements/
The number is stored as a varbinary(8) in QueryStore and UINT64 in Extended Events. This conversion is hard to do in TSQL. I managed to do it in .NET, and get the correct result, but that requires a CLR Function in SQL Server, I guess?
It is silly difficult to do, but look at the code I just posted. It will get the job done in T-SQL. Crazy that we have to hop through hoops like that though.
Thanks, but I could not get the correct number from this.
I got 5945834860049521892 from 0xD283D94D8662DCE4 instead of 15169206896904297700.
DECLARE @decimal AS DECIMAL(20,0)
DECLARE @a BIGINT
SET @a = 0x7fffffffffffffff
SET @decimal = CAST((0xD283D94D8662DCE4 & @a) AS DECIMAL(20,0))
SELECT @decimal
I’m not sure. It seemed to work when I tested it with the query_hash value I had. It also seems to work on the blog post I linked to. Maybe try the query_hash_signed action instead?
Can you get SPID from query hash? (like for example if i am querying QueryStore i want to know SPID associated with each query).
Yes and no.
Yes if you’re querying sys.dm_exec_requests for queries that are happening right now. That would allow you to use the query hash to find a SPID.
No if you’re querying sys.dm_exec_query_stats, sys.dm_exec_procedure_stats, sys.dm_exec_trigger_stats or sys.dm_exec_function_stats. That’s because all of these are simple aggregates of the objects in question in cache. Being aggregates, you can’t associate them with specific SPIDs.
The DMVs are only good for what’s happening immediately in front of me, with zero history at a granular level, or, what has happened in the recent past aggregated.If you want granular details historically, then setting up Extended Events to capture them is the way to go. Query Store can give you more history, with some degree of granularity since it aggregates by the hour (allowing for before & after comparisons, huge deal). However, detailed, historical data, you have to create an Extended Events session.