In the last few Fundamentals posts you were introduced to a couple of ways to limit and control the data stored in the tables in your database. A primary key won’t allow a duplicate value. A foreign key won’t allow a value to be added that doesn’t already exist in the parent table and it will prevent data from being deleted. These are types of constraints on data in your database. There are a bunch of other ways to constrain the data in an effort to ensure that the data stored is exactly what the business needs.
The next few Fundamentals posts will cover several methods of limiting data.
Unique Constraints to Stop Duplicates
When the concept of the primary key was introduced earlier in the series, two different types of keys, natural and artificial, were also discussed. If you recall, one problem with artificial keys is that they don’t constrain the data from a business standpoint. So, while, if you insert the value ‘Frederick’ two different times into a table, the primary key will be unique in both instances with an artificial key, what do you do if you only want one instance of the value ‘Frederick?’ That’s where unique constraints come into play.
Unique constraints are effectively like a second (or third, or fourth) primary key on the table. Just like the primary key, when you create a unique constraint on a column or columns, it will prevent duplicate values from being added to the table for the column, or columns, defined by the unique constraint. Also, like the primary key, you can attach a foreign key constraint to a unique constraint. The same rules and requirements for that foreign key apply as they would to a primary key. Just like the primary key, the query optimizer inside SQL Server can take advantage of a unique constraint to help certain queries run faster.
However, a unique constraint is not a primary key. As I’ve already mentioned, you can have more than one unique constraint on a table where you can only ever have a single primary key. Also, unlike the primary key, you can actually have a NULL value in a unique constraint. But, note that key word and tricky phrase. You can only have a single NULL value on any column in a unique constraint. There are situations that absolutely require a primary key, such as transactional replication (a way to automatically copy data between databases), whereas there are no absolute requirements for a unique index.
| Primary Key | Unique Constraint | |
| Enforce Unique Values | Yes | Yes |
| Support Foreign Key | Yes | Yes |
| Query Optimizer Support | Yes | Yes |
| Multiple Objects | No | Yes |
| Allow Single NULL | No | Yes |
| Special Requirements | Yes | No |
These differences are somewhat subtle, but with this understanding of how they work, you can be much more efficient when you decided when, and how, to use the constraint to satisfy the needs of your business. Let’s see how to create a unique constraint using the SSMS GUI.
Unique Constraints from the GUI
As I pointed out before, one of the main uses you’re going to have for a unique constraint is to provide a mechanism of supplying an alternate, natural key on a table that is using an artificial key like an identity column. For the business database we’re building, the Management.Company table needs a unique constraint on the CompanyName column so that you can’t enter the same name twice. To create the constraint using SSMS, you’ll have to go into the Table Designer window again. You can open this by navigating through the Object Explorer to the appropriate database and table. Right click on the Management.Company table and select “Design” from the context menu. The, by now familiar, Table Designer window will open.
Right click on the Table Designer itself and select “Indexes/Keys…” from the context menu. That will open the Indexes/Keys window that you’ve already seen while working with primary keys. All that will be visible in the current window is the primary key as shown here:
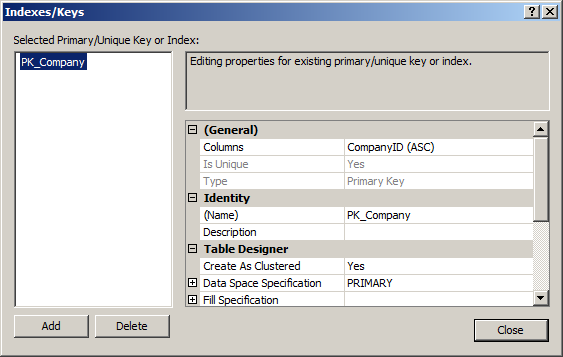
To start creating a unique constraint for this table, you first need to click on the Add button. This will create a default index. This means you’re going to have to do a bunch of edits to various fields. Don’t worry about the fact that information has already been added. The first thing you’ll need to adjust is the columns. SQL Server will have selected the first column in the table, probably CompanyID. Click on the ellipsis next to the “Columns” row. This will open the Index Columns window. The same column will still be selected by default. The ColumnName is a drop down window. You can select the column you want as the unique constraint, CompanyName. Once selected it will look like this:
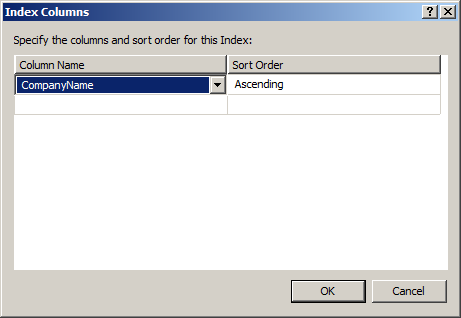
Clicking the OK button from this window will close it and put the value, or values, selected into the Columns row in the Indexes/Keys window. Next, you need to change the Type from Index to Unique Key. Unique Key in this case is just another term for unique constraint. You’re going to notice all the time that certain parts of SQL Server refer to an object one way and other parts refer to it another way. This is just an artifact from different development teams using slightly different standards.
Once you select Unique Key, you should see the Is Unique column change, automatically from a value of ‘No’ to a value of ‘Yes’ and it will be greyed out so that you can’t adjust it manually. This makes sense because we’re creating a unique constraint. Finally, go a little farther down on the window and select the existing Name value. Type in a new name unless you want to use the default value of ‘IX_Company.’ That’s it. The window should look something like this:
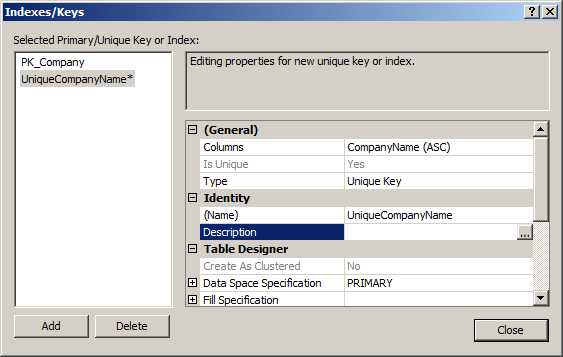
Click the Close button and then save the changes to the table. Because a unique constraint is an alternate key, it’s not actually displayed in the Constraint folder under the database. It’s part of the Keys folder instead. Just refresh the display in the Object Explorer window like normal and you’ll see the unique constraint you just finished creating.
Conclusion
Taking control of the data in your database means that data will be cleaner. You don’t have to enforce unique constraints, but, where data is unique, doing so helps ensure that data is more accurate. Also, having unique constraints helps when we start talking about performance in the database.
The next Fundamentals post will show how to create a unique constraint using T-SQL.