Everyone knows that you only get a single clustered index, right? Wouldn’t it be great though if you could have two clustered indexes?
Well, you can. Sort of. Let’s talk about it.
Two Clustered Indexes
First I’m going to create a table:
DROP TABLE IF EXISTS dbo.od;
GO
SELECT pod.PurchaseOrderID,
pod.PurchaseOrderDetailID,
pod.DueDate,
pod.OrderQty,
pod.ProductID,
pod.UnitPrice,
pod.LineTotal,
pod.ReceivedQty,
pod.RejectedQty,
pod.StockedQty,
pod.ModifiedDate
INTO dbo.od
FROM Purchasing.PurchaseOrderDetail AS pod;With that in place, let’s start with a clustered index:
CREATE CLUSTERED INDEX TestCIndex ON od (ProductID);And, a query to test with:
SELECT od.PurchaseOrderID,
od.PurchaseOrderDetailID,
od.DueDate,
od.OrderQty,
od.ProductID,
od.UnitPrice,
od.LineTotal,
od.ReceivedQty,
od.RejectedQty,
od.StockedQty,
od.ModifiedDate
FROM dbo.od
WHERE od.ProductID
BETWEEN 500 AND 510
ORDER BY od.ProductID;This results in the following execution plan:

OK. Well done, Grant. That’s how a clustered index works. The data is sorted and stored at the leaf level based on the key column or columns. So a query like this where the filtering criteria is on the clustered key, and the ordering criteria is on the clustered key, with no additional filtering required, gets a plan that’s an ordered seek on the clustered index. You widget, you.
Fine. Let’s drop that index, and create a new one:
DROP INDEX IF EXISTS TestCIndex ON dbo.od
CREATE INDEX TestNCIndex
ON dbo.od (ProductID)
INCLUDE (
PurchaseOrderDetailID,
DueDate,
OrderQty,
PurchaseOrderID,
UnitPrice,
LineTotal,
ReceivedQty,
RejectedQty,
StockedQty,
ModifiedDate
);If we run our query again, this is now the execution plan:
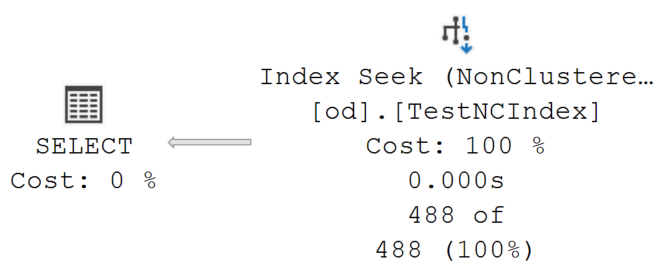
Because we have stored all the columns of the table as INCLUDE columns at the leaf level of the nonclustered index, we effectively have a second clustered index.
Now, don’t get too excited, let’s talk about it.
It’s Not a Clustered Index
First up, I didn’t mention performance above, so let’s mention it now. The clustered index performed as follows:
2.99ms
30 reads
The nonclustered index:
3.16ms
29 reads
If we round, these ran in the same amount of time, 3 milliseconds. Yeah, there’s a 6% variance there over 100 executions, but that’s pretty small, especially when talking microseconds. So we can say, they ran in the same amount of time.
What about the reads?
Let’s look at one other query, against each index:
SELECT i.NAME,
i.type_desc,
s.page_count,
s.record_count,
s.index_level
FROM sys.indexes i
JOIN sys.dm_db_index_physical_stats(DB_ID(N'AdventureWorks'), OBJECT_ID(N'dbo.od'), NULL, NULL, 'DETAILED') AS s
ON i.index_id = s.index_id
WHERE i.OBJECT_ID = OBJECT_ID(N'dbo.od');We get the results back and the nonclustered index consists of 84 pages while the clustered index consists of 87. What the heck?
Well, look, the nonclustered index is not a clustered index. You can tell because the results for the query above are going to show just the pages for the clustered index, or, they’re going to show the nonclustered index pages as well as the pages for the heap table. Yeah, just because we’re defining an index that includes all the data, doesn’t mean the data is still not stored somewhere. How many pages are in the heap? 87.
Oh. Why?
I didn’t get into the weeds on this, but I’m pretty sure it has to do with the row locator. See, for a heap, you store the RID along with the row. For a clustered index, of course, you don’t do that… but… this isn’t a unique clustered index, so along with the key, we need a uniquifier to give us a row locator. Hence, just a little bigger, with the possibility for just slightly more reads.
Conclusion
Again, don’t get excited. I’m absolutely not suggesting that, ta-da, you get two, or more, clustered indexes for free. There are serious ramifications here. You’re doubling (or close to it), your storage. You’re adding overhead to every single write operation. TANSTAAFL certainly applies here.
However, if you’re willing to pay the cost, yeah, you can have two clustered indexes. Effectively. Kind of.
I’ve wondered occasionally about doing exactly that. I have far more storage space than I can possibly use, and two principal orders in which data is accessed. I’ve wondered if duplicating the entire main table in this second order might not speed things up. As usual, most of the activity is reads – writes are rare and contention during writes is effectively zero.
I’d try it. Especially if you’re that light on writes. This has storage implications, certainly. However, those can be kind of ignored by a lot of people these days. The real kicker for me is maintenance and data manipulation. That will absolutely have more implications than just looking at one query’s performance.
Oh.. nice…
“I have heaps of space! Sucks to be everyone else that has very little and cannot get any!”
(yes, I am being facetious and not nasty in any way at all 😀 )
You can put a clustered index on an indexed view providing it doesn’t conflict with the clustered index on the table.
Found that out the hard way.