If you have been reading through all my fundamentals posts and following along, you have built a small sample database, loaded it with data, and learned how to retrieve the data from it. You’ve also learned how to relate one table to another through T-SQL JOIN statements. But that relationship is very temporary. It will last only as long as it takes for that query to run. To create a database that enforces the relationships between the tables, you need to work with declarative referential integrity (DRI), frequently shortened to referential integrity(RI).
DRI is the foundation on which the relational part of the relational storage engine is built. It’s not just a nice thing to do for your database. It’s actually a fundamental piece of how SQL Server works. DRI is taken into account when you write queries that JOIN one table to another. It can directly affect performance as well as ensure that your data is accurate and has integrity.
Referential Integrity Explanations
In my first few posts in the series, we talked about how the rules of normalization or a dimensional model could drive relationships between tables. The[CK1]Â relationships are built on the concept that one table has a column, or columns, that uniquely identify rows in that table. Another table has those same columns in order to create a relationship between the two tables. DRI comes into play by first, creating a constraint on the column(s) that uniquely identify the row. This particular constraint is called a Primary Key. This graphic illustrates these types of relationships:
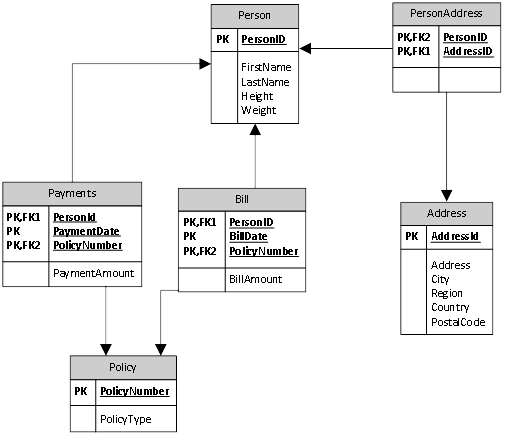
Tables can actually have multiple unique values. Any other unique value is usually referred to as an Alternate Key. These columns could be used as the primary key instead of the one you selected, but, usually because of business decisions, but frequently because of structural choices that you make, these other columns are not.
Once you pick the primary key and define it for SQL Server, you can’t put duplicate data into that column. SQL Server will absolutely prevent it from happening. It will only ever allow unique values. For example, if you define a column such as FirstName as a primary key (not a good choice) then you can only have a single row with a value of ‘Richard.’ If you attempt to add another value with ‘Richard’ you won’t be able to. But if you add a value of ‘Rich’ you will. If you need to put duplicate information into the field or fields that you defined as your primary key, then that is not your primary key because you can only ever have a unique value for a primary key. That’s the definition of it.
After defining the  primary key for a table, the child tables that will relate to the parent table should have the same field(s) with the same data type in them as you can see above with the relationship between the Address and the PersonAddress table. This is how you already wrote queries to relate two tables. But now you’re going to add a constraint to that child table called a foreign key. A foreign key will ensure that the only data that can be put into the column in the child table already exists in the parent table as a primary key. For example, an address has been added to the Address table above and it generated a primary key value of 42. Let’s assume for the moment, that’s the only row in the table. With a foreign key constraint in place, you can’t add a row to the PersonAddress table that has a value in the AddressID table that is not equal to 42 because that is the only value available to you. The same thing works with lots of rows and values. You just have more choices, but you’re still limited to just those choices. Further, you can’t delete the parent row without all of the child rows that are related to it being deleted first. You have established Referential Integrity.
The integrity of RI is defined by the fact that there is a defined primary key that will only ever allow unique values. That primary key is used to establish relationships with other tables. The integrity of those relationships is ensured by a foreign key so that you can only use values in the child table that exist in the parent and the parent can’t be removed unless there are no more values related to it in the child. This is what makes up Referential Integrity. It’s fundamentally about ensuring that your data is well structured and you won’t get any surprises, unmatched foreign key values or missing parent values, etc., that will absolutely skew the results of queries.
Conclusion
So, that’s the basics of primary and foreign keys. Our next post will be a short discussion around a slightly controversial topic relating to primary keys. Then, the post after that will get into how to use SSMS and T-SQL to create primary key constraints.