At a recent all-day seminar on query performance tuning I was asked a question that I didn’t know the answer to: “How do join hints affect adaptive joins?”
I don’t know. Let’s find out together.
Adaptive Joins
Here’s a query that we can run against AdventureWorks:
SELECT p.Name,
COUNT(th.ProductID) AS CountProductID,
SUM(th.Quantity) AS SumQuantity,
AVG(th.ActualCost) AS AvgActualCost
FROM Production.TransactionHistory AS th
JOIN Production.Product AS p
ON p.ProductID = th.ProductID
GROUP BY th.ProductID,
p.Name;
Without a columnstore index in SQL Server 2017, the execution plan looks like this:

Let’s introduce a columnstore index:
CREATE NONCLUSTERED COLUMNSTORE INDEX ix_csTest
ON Production.TransactionHistory
(
ProductID,
Quantity,
ActualCost
);
Now, if we run the same query, the execution plan changes to use an adaptive join like this:
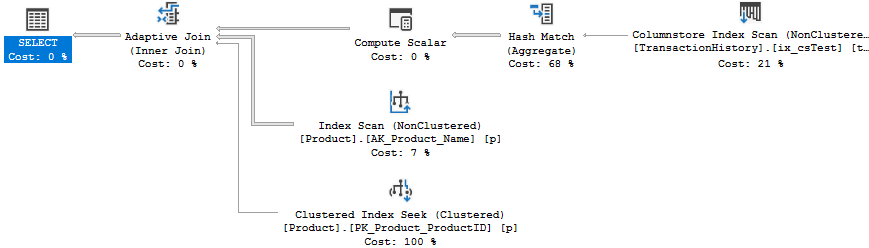
You can read more on adaptive joins here if this is new behavior. Now, what if we decide that we just want to see a hash join all the time?
Adding a Join Hint
I’m not a giant fan of any of the query hints. Yeah, I use them. Heck, the OPTIMIZE FOR hint I advocate for (depending on the situation, etc.), but even that one makes me feel a little uncomfortable when I use it. However, the hints exist for a reason and there are valid choices in their use. Since an adaptive join may not perform as well as a hash join, we might see a situation where the hash join is superior. This means we decide to use the hint like this:
SELECT p.Name,
COUNT(th.ProductID) AS CountProductID,
SUM(th.Quantity) AS SumQuantity,
AVG(th.ActualCost) AS AvgActualCost
FROM Production.TransactionHistory AS th
INNER HASH JOIN Production.Product AS p
ON p.ProductID = th.ProductID
GROUP BY th.ProductID,
p.Name;
Capturing the execution plan, it now looks like this:
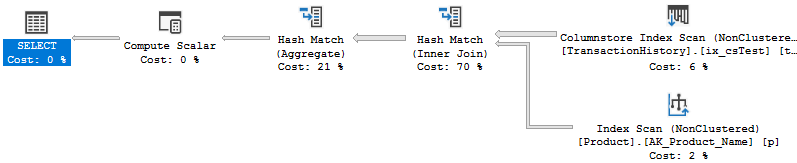
It’s now using a hash join as we told it to. However, notice the plan shape. More importantly, notice the size of the pipes representing data flow. Before I explain what’s going on, what about performance? On average the adaptive join ran in 70ms with 70 reads. On average the hinted query ran in 92 with 70 reads. What’s going on?
Differences Caused by a Join Hint
The key thing to remember is that a hint is very bad name. They are not hints. They are commandments. It’s not a suggestion or an idea that we’re imparting to the optimizer, “Please consider using a hash join.” The optimizer considered it, and rejected it in favor of the adaptive join. Why?
As always, the devil is in the details, or in this case, the properties. If we look at the Columnstore Index Scan from the plan with the Adaptive Join, we see a couple of interesting data points:
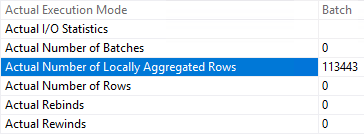
I’ve highlighted the interesting bit. “Actual Number of Locally Aggregated Rows” is part of aggregation push down, explained by the amazing Niko Negebauer here and here. Basically, the aggregation is occurring with the data access. So while there is a Hash Match operator for the aggregation, actually, the active part of the aggregation was performed within the columnstore. That’s why the Actual Number of Rows coming out of the columnstore index itself is 0, but the number of rows coming out of the Hash Match Aggregate is 441.
So… why not another aggregate push down when we used the hint? Because the hint says, we MUST use a hash join. At that point the optimizer has no choices on where, when, how it does data processing. It must, first, ensure that a hash join is used, so it does. First thing out of the gate, hash join. Then a hash aggregate. This difference in behavior results in a 24% decrease in performance. The only interesting thing is that the reads remained consistent. This means that it was just the processing of the join that added overhead.
Conclusion
There’s nothing really all that fancy about an adaptive join if you decide to apply a join hint. The adaptive join doesn’t take control away from the optimizer. You can choose how you want the query processed. However, that doesn’t automatically mean you’re going to be happy with the results.
Want to learn more about how to use tools like execution plans to do query tuning? I’ve got one last class scheduled this year.
Please join me in Munich on October 26, 2018. Go here now to join the class.
[…] Grant Fritchey looks at the combination of adaptive joins and query hints which specify join type: […]
“You can read more on adaptive joins here if this is new behavior.”… I can, unless there’s no link / URL.
Apologies. I’ve updated the text and added the link here: https://www.scarydba.com/2018/02/27/adaptive-joins/